
[AI]클로드 섀넌 다이버전스: 확률 분포 간의 차이를 측정하는 지표 (Kullback-Leibler Divergence)
클로드 섀넌 다이버전스(Kullback-Leibler Divergence, KL Divergence)는 확률 분포 간의 차이를 측정하는 지표로, 정보 이론과 통계학에서 중요한 역할을 합니다. 두 확률 분포가 얼마나 다른지를 나타내는 KL 다이버전스는 두 분포 간의 상대적인 정보 양을 측정합니다.
1. 정의:
KL 다이버전스는 주로 두 확률 분포 P와 Q 사이의 차이를 측정합니다. P와 Q가 동일한 분포라면 KL 다이버전스는 0이 되며, 값이 클수록 두 분포는 서로 다릅니다. 수식으로 나타내면 다음과 같습니다.
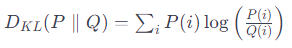
2. 해석:
KL 다이버전스는 정보량으로 해석될 수 있습니다. 두 분포의 확률 값이 유사할수록 KL 다이버전스는 작아지며, 값이 커질수록 두 분포 간의 차이가 크다는 것을 나타냅니다.
3. 특징:
비대칭성:
- KL 다이버전스는 비대칭적이며, 식은 아래와 같습니다.
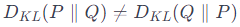
비음수성:
- KL 다이버전스는 항상 0 이상의 값을 가지며, 두 확률 분포가 동일하면 0이 됩니다.
결합 확률 분포:
- KL 다이버전스는 두 확률 분포의 결합 확률 분포에 대해서도 확장될 수 있습니다.
4. 응용 분야:
머신 러닝:
- 확률 분포 간의 유사성을 측정하여 모델의 성능을 평가하거나, 분포 간의 변화를 감지하는 데 사용됩니다.
정보 검색:
- 검색된 문서와 사용자 쿼리 사이의 유사성을 측정하여 검색 품질을 개선하는 데 활용됩니다.
통계학:
- 표본 분포와 이론적 분포 사이의 차이를 측정하여 통계적 추론을 수행하는 데 사용됩니다.
5. 주의사항:
무한 값 가능성:
- KL 다이버전스는 무한대의 값을 가질 수 있어 주의가 필요합니다.
0으로 나누기 문제:
- 만약 Q(i)가 0인 경우, 로그 내의 분모가 0이 되어 무한대 값을 갖게 됩니다.
6. 예시:
KL 다이버전스는 코딩 분포와 실제 분포 사이의 차이를 측정하여 압축 알고리즘의 성능을 평가하는 데 사용되거나, 생성 모델의 학습 중에 두 확률 분포 간의 거리를 최소화하는 목적 함수로 활용될 수 있습니다.
7. 미래 전망:
KL 다이버전스는 다양한 분야에서 활용되며, 특히 머신 러닝 및 딥 러닝에서 모델 간의 차이나 변화를 측정하는데 중요한 도구로 계속 사용될 것으로 예상됩니다. 새로운 응용 분야에서의 활용 및 발전이 더 기대됩니다.
클로드 섀넌 다이버전스(KL Divergence)는 확률 분포 간의 차이를 측정하는 지표로, P와 Q 두 확률 분포의 차이를 나타냅니다. 이 지표는 머신 러닝, 통계학, 정보 이론에서 모델 간의 유사성 평가, 검색 품질 개선, 통계적 추론 등에 활용됩니다.
KL 다이버전스는 비대칭적이며 항상 0 이상의 값을 가지는 특징이 있습니다. 그리고 무한 값 가능성 및 0으로 나누기 문제에 대한 주의가 필요합니다.
이 지표는 예를 들어, 코딩 분포와 실제 분포 사이의 차이를 측정하여 압축 알고리즘의 성능을 평가하거나, 생성 모델의 학습 중에 두 확률 분포 간의 거리를 최소화하는 목적 함수로 활용될 수 있습니다.
KL 다이버전스는 미래에도 머신 러닝 및 딥 러닝에서 모델 간의 차이나 변화를 측정하는데 중요한 도구로 활용될 것으로 예상되며, 새로운 응용 분야에서의 활용 및 발전이 기대됩니다.


